Abstract
Traditional data mining usually deals with data from a datasets from different sources in different domains. These datasets representation, distribution, scale and density. How to unlock the connected) datasets is paramount in the big data research, essentially This calls for advanced techniques that can fuse the knowledge from mining task. This paper summarizes the data fusion methodologies, feature level-based, and the semantic meaning-based data fusion divided into four groups: multi-view learning-based, similarity-based, methods. These methods focus on knowledge fusion rather than between cross-domain data fusion and traditional data fusion studied introduce high-level principles of each category of methods, but also real big data problems. In addition, this paper positions existing works between different data fusion methods. This paper will help a wide in big data projects.
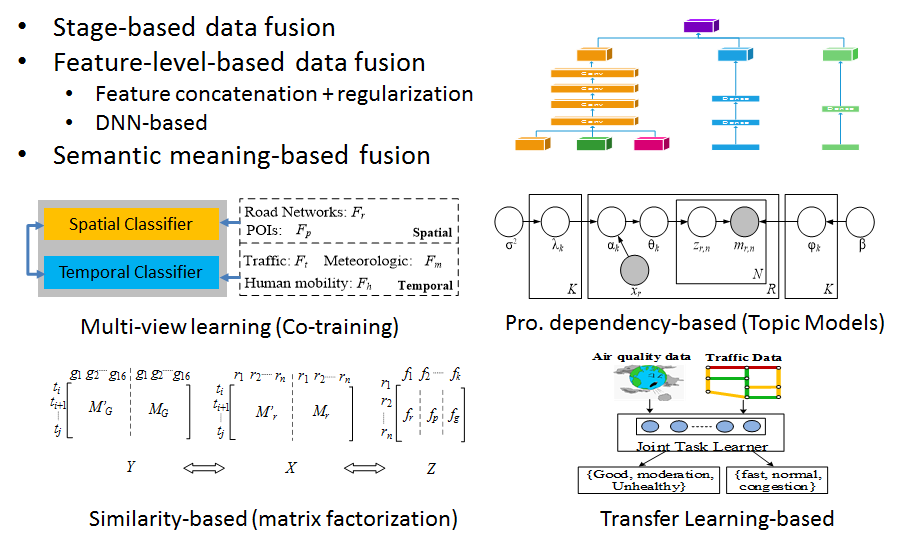
A tutorial can be found here:
- The stage-based data fusion methods (slide decks)
- The feature-level-based data fusion methods (slide decks)
- The semantic meaning-based data fusion methods
- The multi-view-based data fusion methods (slide decks)
- The similarity-based data fusion methods (slide decks)
- The probabilistic-based data fusion methods (slide decks)
- Transfer learning-based data fusion methods (slide decks)