 CityNoise was a project led by Dr. Yu Zheng in Microsoft Research. The project aims to diagnose a city’s noise pollution with crowdsensing and ubiquitous data. It reveals the fine-grained noise situation throughout a city and analyzes the composition of noises in a particular location, by using 311 complaint data together with road network data, points of interests, and social media.
CityNoise was a project led by Dr. Yu Zheng in Microsoft Research. The project aims to diagnose a city’s noise pollution with crowdsensing and ubiquitous data. It reveals the fine-grained noise situation throughout a city and analyzes the composition of noises in a particular location, by using 311 complaint data together with road network data, points of interests, and social media.
Background and Motivation
Many major cities are suffering from noise pollution, which compromises working efficiency and even impair people’s mental health in a long run. Modeling citywide noises, however, is very challenging, given the following three reasons. 1) Urban noises change over time quickly and vary by location significantly. This means we need to deploy millions of sensors to monitor a city’s noise. 2) The measurement of noise pollution depends on noise levels and people’s tolerance to noise; the latter changes over time. 3) Noise is usually a mixture of multiple sound sources. Diagnose the composition of noises solely based on sound sensors is very difficult.
New York City (NYC) has opened a platform titled 311 to allow people to complain what they feel annoyed by through a mobile app or making a phone call; noise is the third largest category of complaints in the 311 data. As each complaint about noises is associated with a location, time stamp, and a fine-grained noise category, such as loud music or construction noises, the data is actually a result of “human as a sensor” and “crowd sensing”, containing rich human intelligence that can help diagnose urban noises. Specifically, the more 311 calls are made in a location, the louder the real noise could be in the location. In addition, the distribution of these 311 complaints over different noise categories may describe the composition of noises in the location.
In short, the 311 data contains rich human intelligence that can help us understand noise pollution from people’s perspectives. It is even better than raw sensor data. However, the data is very sparse, as there are not always people complaining about noise anytime and anywhere.
Goal
In this project, we infer the fine-grained noise situation (consisting of a noise pollution indicator and the composition of noises) of different time of day for each region of NYC, by using the 311 complaint data together with social media, road network data, and Points of Interests (POIs). The fine-grained information of noise can inform people’s daily decision making (e.g. finding a quite a hotel to stay) and official’s policy making on tackling noise pollution.
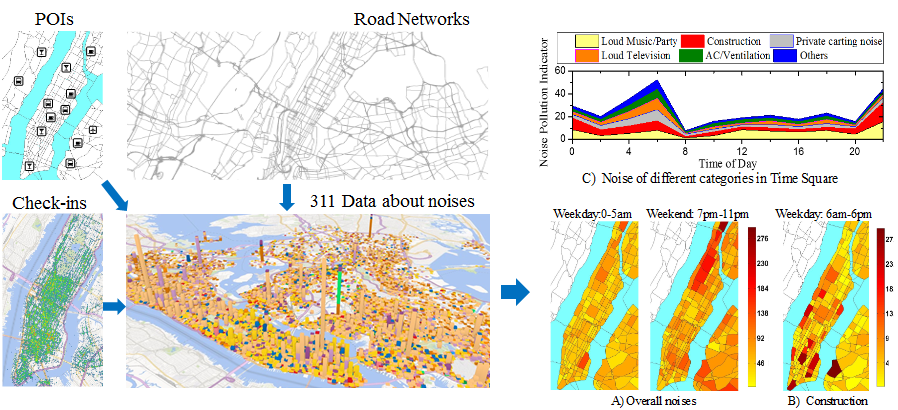
Methodology
We model the noise situation of NYC with a three dimension tensor, where the three dimensions stand for regions, noise categories, and time slots, respectively. We build anther three matrices (X, Y, Z) from road network data, POIs, and check-in data. By factorizing the three matrices together with the tensor, we supplement the sparse tensor, therefore, recovering the noise situation throughout NYC. The insight supporting the method is that the three additional datasets have a strong correlation with urban noises. Thus, the knowledge learned from the three datasets can tackle the data sparsity problem in 311 data.
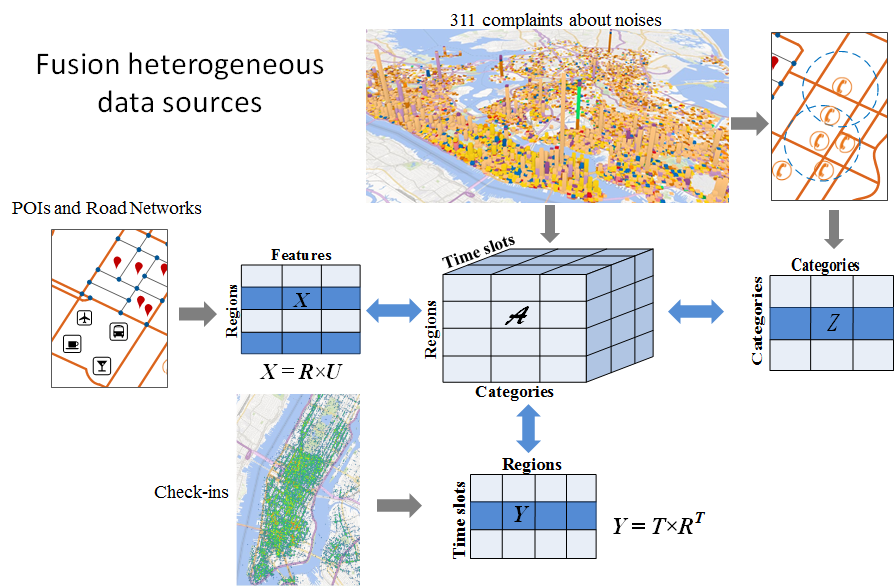
We build a matrix X based on POIs and road network data, where a row stands for a region and a column denotes a feature, e.g. the number of intersections in the region and distribution of POIs across different categories. Matrix ? incorporates the similarity between two regions in terms of their geographic features. Intuitively, regions with similar geographic features could have a similar noise situation.
We build another matrix Y based on users check-in data from social networks, where a row stands for a time slot and a column denotes a region. Each entry represents the number of check-ins people have made in a particular region and at a particular time interval. Matrix ? reveals the correlation between different time slots in terms of the distribution of check-ins indifferent regions. Two time slots sharing a similar user check-in pattern could have a similar noise situation. Matrix Y also implies the similarity between two regions in terms of people’s check-in patterns in temporal spaces.
Results
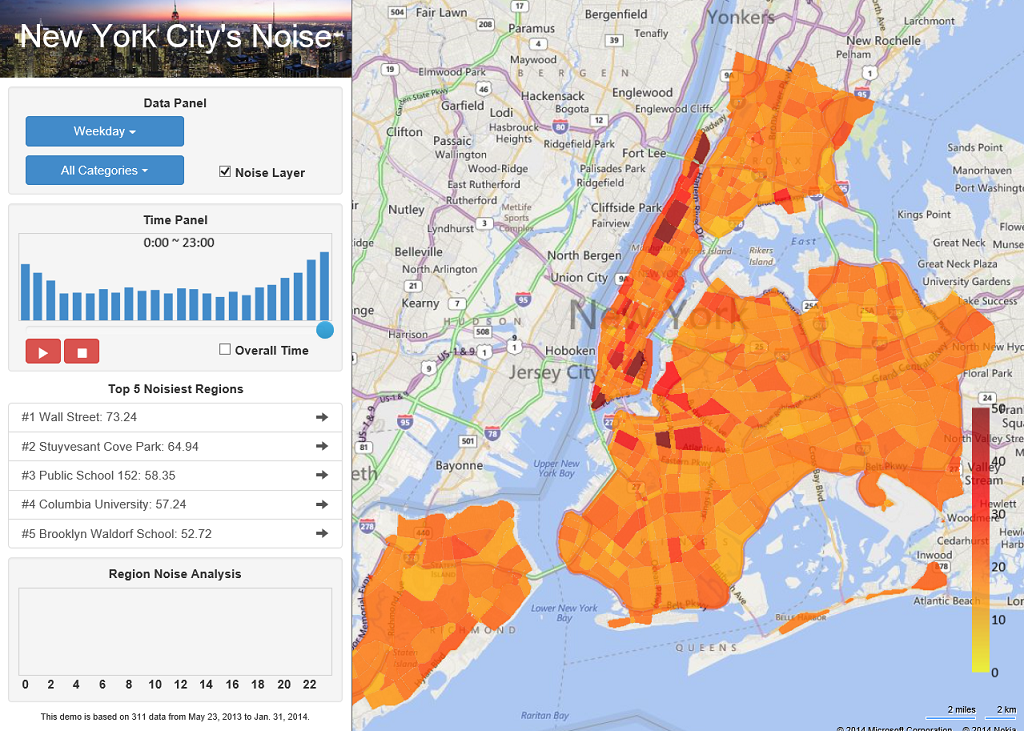
Data and Codes
People

Yu Zheng
Vice President and Chief Data Scientist, JD Technology Group
Publications
