Concept (中文主页)
Urban computing is a process of acquisition, integration, and analysis of big and heterogeneous data generated by a diversity of sources in urban spaces, such as sensors, devices, vehicles, buildings, and human, to tackle the major issues that cities face, e.g. air pollution, increased energy consumption and traffic congestion. Urban computing connects unobtrusive and ubiquitous sensing technologies, advanced data management and analytics models, and novel visualization methods, to create win-win-win solutions that improve urban environment, human life quality, and city operation systems. Urban computing also helps us understand the nature of urban phenomena and even predict the future of cities. A survey paper on urban computing:
Yu Zheng, Licia Capra, Ouri Wolfson, Hai Yang. Urban Computing: concepts, methodologies, and applications. ACM Transaction on Intelligent Systems and Technology (ACM TIST). 2014.
Urban computing used to be a research project in Microsoft Research, led by Dr. Yu Zheng from March 2008 to February 2018. By analyzing the big data generated in urban spaces, a series of urban computing applications have been enabled as follows. One of core research problems is to fuse data across different domains. The other is to learn knowledge from spatio-temporal data, e.g. trajectories.
Yu Zheng. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Transactions on Big Data, vol. 1, no. 1. 2015. (A Tutorial)
Yu Zheng. Trajectory Data Mining: An Overview. ACM Transaction on Intelligent Systems and Technology. 2015, vol. 6, issue 3. (A Tutorial)
News
- 2017.4.9: We are organizing the 6th International Workshop on Urban Computing (UrbComp 2017) in conjunction with KDD 2017.
- 2017.4.9: A tutorial on Cross-domain Data Fusion. Download slide decks for free!
Representative Research
 |
Smart Transportation
|
The Intelligent Environment
|
Big Data-Driven Urban Planning
|
Urban Economy using Big Data
|
Detecting Urban Anomalies
|
Urban Energy
|
|
Intelligent Environment
The Intelligent Environment
Tackling Air Pollution Using Big Data
Refer to Urban Air’s homepage for more details.
A. Real-Time Air Quality Inference
Public Website: http://urbanair.msra.cn/ Install Windows phone App here.
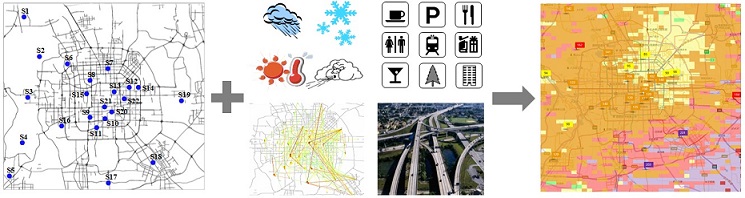
Goal: We infer the real-time and fine-grained air quality information throughout a city, based on the (historical and real-time) air quality data reported by existing monitor stations and a variety of data sources we observed in the city, such as meteorology, traffic flow, human mobility, structure of road networks, and point of interests (POIs).
Methodology: We propose a semi-supervised learning approach based on a co-training framework that consists of two separated classifiers. One is a spatial classifier based on an artificial neural network (ANN), which takes spatially-related features (e.g., the density of POIs and length of highways) as input to model the spatial correlation between air qualities of different locations. The other is a temporal classifier based on a linear-chain conditional random field (CRF), involving temporally-related features (e.g., traffic and meteorology) to model the temporal dependency of air quality in a location.
Publication:
[1] Yu Zheng, Furui Liu, Hsun-Ping Hsie. U-Air: When Urban Air Quality Inference Meets Big Data. 19th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2013).
[2] Yu Zheng, Xuxu Chen, Qiwei Jin, Yubiao Chen, Xiangyun Qu, Xin Liu, Eric Chang, Wei-Ying Ma, Yong Rui, Weiwei Sun. A Cloud-Based Knowledge Discovery System for Monitoring Fine-Grained Air Quality. MSR-TR-2014-40.
B. Forecast Fine-Grained Air Quality
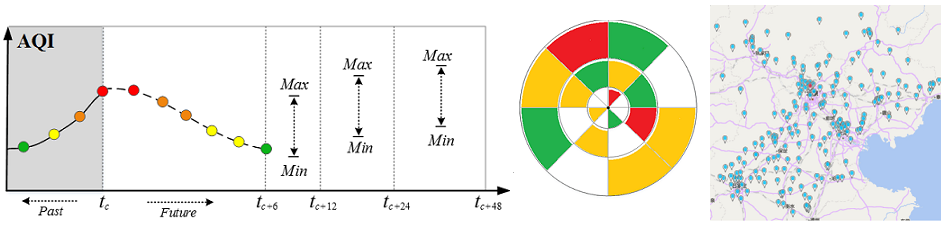
Goal: We forecast the reading of an air quality monitoring station in the next 48 hours, using a data-driven method that considers the current meteorological data, weather forecasts, and the air quality data of the station and that of other stations within a few hundred kilometers to the station.
Methodology: Our predictive model is comprised of four major components: 1) a linear regression-based temporal predictor to model the local factor of air quality, 2) a neural network-based spatial predictor modeling the global factors, 3) a dynamic aggregator combining the predictions of the spatial and temporal predictors according to the meteorological data, and 4) an inflection predictor to capture the sudden changes of air quality.
Publication:
[1] Yu Zheng, Xiuwen Yi, Ming Li, Ruiyuan Li, Zhangqing Shan, Eric Chang, Tianrui Li. Forecasting Fine-Grained Air Quality Based on Big Data. In the Proceeding of the 21th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2015). (Data)(PPT)
C. Suggesting Locations for New Station Deployment
Given a limited budget to build a few additional air quality monitoring stations, where shall we put them? The research solves this problem from the perspective of maximizing the inference accuracy and stability.
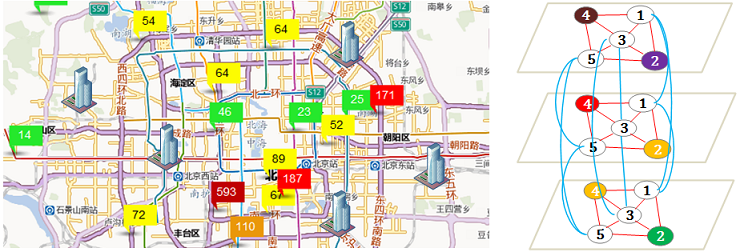
Publication:
[1] Hsun-Ping Hsieh*, Shou-De Lin, Yu Zheng. Inferring Air Quality for Station Location Recommendation Based on Big Data. In the Proceeding of the 21th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2015).
D. Identifying the Root Cause of Air Pollution
The research identifies the spatio-temporal causality between air pollutants of different cities, suggesting the root cause of air pollution based on AI and big data technology.
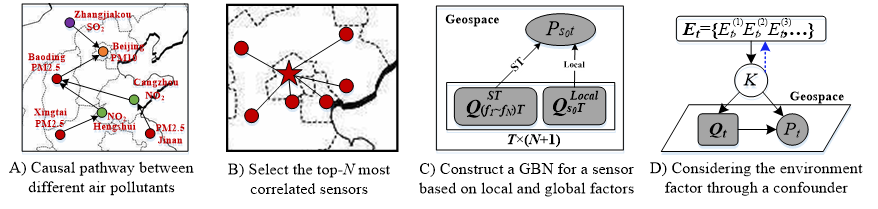
Publication:
[1] Julie Yixuan Zhu, Chao Zhang, Huichu Zhang, Shi Zhi, Victor O.K. Li, Jiawei Han, and Yu Zheng, pg-Causality: Identifying Spatiotemporal Causal Pathways for Air Pollutants with Urban Big Data. IEEE Transactions on Big Data. DOI: 10.1109/TBDATA.2017.2723899
Media Coverage:
[1] Analyzing newly available data about the intricacies of urban life could make cities better.” MIT Technology Review. 2013.8.21
[2] Interviewed by IFeng.com. Big data can predict air quality. 2013.11.29 (In Chineses)
[3] ComputerWorld: Microsoft predicts China’s air pollution with data analysis, 2015.6.11
[4] Ming Pao (HK): Microsoft predicts air quality with big data, 2015.6.10
[5] GeekWire Reporter: What Microsoft Research is doing to help Beijing air pollution. 2015.11.30
[6] NBC News: Microsoft, IBM Eye Big Business Opportunity in China’s Air Pollution. 2015.12.28
[7] Reuters: Tech giants spot opportunity in forecasting China’s smog, 2015.12.28
[8] China Daily: Microsoft, IBM eye Technology to forecast air pollution in China. 2016.1.19
________________________________________________________
Diagnosing Urban Noise Using Big Data
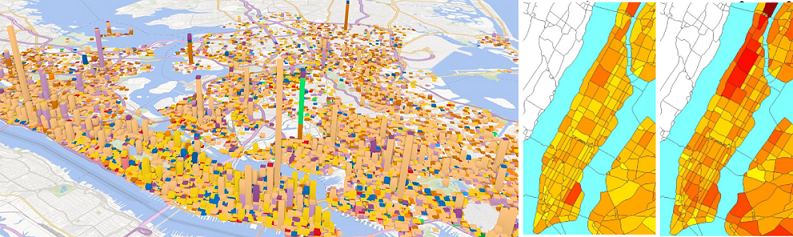
Refer to the homepage of CityNoise for details.
Goal: we infer the fine-grained noise situation (consisting of a noise pollution indicator and the composition of noises) of different times of day for each region of NYC, by using the 311 complaint data together with social media, road network data, and Points of Interests (POIs).
Methodology: We model the noise situation of NYC with a three dimension tensor, where the three dimensions stand for regions, noise categories, and time slots, respectively. Supplementing the missing entries of the tensor through a context-aware tensor decomposition approach, we recover the noise situation throughout NYC. The information can inform people and officials’ decision making.
Publication:
[1] Yu Zheng, Tong Liu, Yilun Wang, Yanchi Liu, Yanmin Zhu, Eric Chang. Diagnosing New York City’s Noises with Ubiquitous Data. In Proceedings of the 16th ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp 2014).
[2] Tong Liu, Yu Zheng, Lubin Liu, Yanchi Liu, Yanmin Zhu. Methods for Sensing Urban Noises. MSR-TR-2014-66, May 2014.
[3] Yilun Wang, Yu Zheng, Tong Liu. A Noise Map of New York City. In Proc. of Ubicomp 2014, Demo.
________________________________________________________________
Predicting Urban Water Quality Based on Big Data
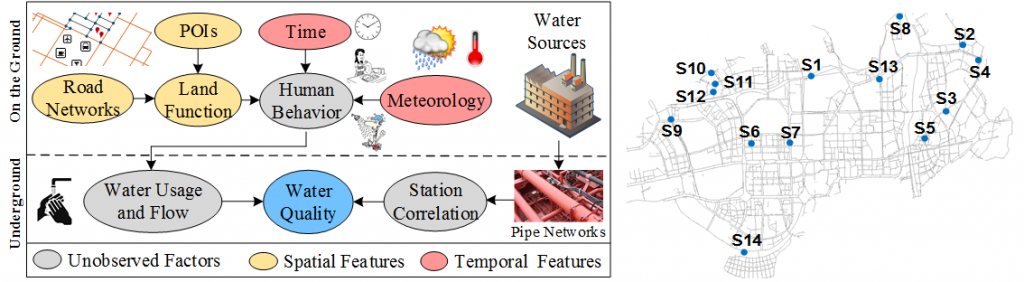
Urban water quality is of great importance to our daily lives. Prediction of urban water quality help control water pollution and protect human health. In this work, we forecast the water quality of a station over the next few hours, using a multitask multi-view learning method to fuse multiple datasets from different domains. In particular, our learning model comprises two alignments. The first alignment is the spaio-temporal view alignment, which combines local spatial and temporal information of each station. The second alignment is the prediction alignment among stations, which captures their spatial correlations and performs co-predictions by incorporating these correlations. This approach has been evaluated based on the data of Shenzhen city in China.
Publication:
[1] Ye Liu, Yu Zheng, Yuxuan Liang, Shuming Liu, David S. Rosenblum, Urban Water Quality Prediction based on Multi-task Multi-view Learning , in Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016)
Smart Transportation
Intelligent Transportation
Large-Scale Dynamic Taxi Ridesharing Service
Abstract: We present a large-scale taxi ridesharing service, which efficiently serves real-time requests sent by taxi users and generates ridesharing schedules that reduce the total travel distance significantly. We first propose a taxi searching algorithm using a spatio-temporal index to quickly retrieve candidate taxies that could satisfy a user query. A schedule allocation algorithm is then proposed to check each candidate taxi so as to insert the user’s trip into the schedule of the taxi. Our service can serve 40% additional taxi users while saving 15% travel distance over no ridesharing on average.
Publications:
[1] Shuo Ma, Yu Zheng, Ouri Wolfson. T-Share: A Large-Scale Dynamic Taxi Ridesharing Service. IEEE International Conference on Data Engineering (ICDE 2013) Best Paper Runner-up Award.
[2] Shuo Ma*, Yu Zheng, Ouri Wolfson. Real-Time City-Scale Taxi Ridesharing. IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 27, No. 7, July 2015. [Codes] [Data]
Travel Time Estimation of a Path Based on Trajectories
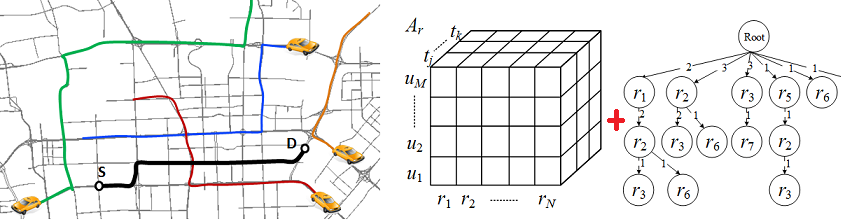
Abstract: We propose a citywide and real-time model for estimating the travel time of any path (represented as a sequence of connected road segments) in a city instantly, based on the GPS trajectories of vehicles received in current time slots and over a period of history as well as map data sources. The problem has not been well solved yet given the following three challenges. The first is the data sparsity problem, i.e., many road segments may not be traveled by any GPS-equipped vehicles in present time slot. Second, for the fragment of a path with trajectories, they are multiple ways of using (or combining) the trajectories to estimate the corresponding travel time. Finding an optimal combination is a challenging problem. Third, we need to instantly answer users’ queries which may occur in any part of a given city. This calls for an efficient, scalable and effective solution that can enable a citywide and real-time travel time estimation.
Publications:
[1] Yilun Wang, Yu Zheng, Yexiang Xue. Travel Time Estimation of a Path using Sparse Trajectories. In Proceedings of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014). (Data and codes)
Smart Driving Directions Based on Taxi Trajectories

Goal: In this research, we aim to mine the time-dependent and practically quickest driving route for end users using GPS-equipped taxicabs traveling in a city.
Insight: The time that a driver traverses a route depends on three aspects: 1) The physical feature of a route, such as distance, the number of traffic lights and direction turns; 2) The time-dependent traffic flow on the route; 3) A user’s drive behavior. Thus, a good routing service should consider these three aspects (routes, traffic and drivers), which are far beyond the scope of the shortest path computing.
GPS-equipped taxis can be regarded as mobile sensors probing traffic flows on road surfaces, and taxi drivers are usually experienced in finding the fastest (quickest) route to a destination based on their knowledge. Consequently, the trajectories of taxicabs already have the knowledge of experienced drivers, physical routes and traffic conditions.
 |
In the beginning of this work, we mine smart driving directions from the historical GPS trajectories of a large number of taxis, and provide a user with the practically fastest route to a given destination at a given departure time. We build our system based on a trajectory dataset generated by over 33,000 taxis in a period of 3 months. According to extensive synthetic experiments and in-the-field evaluations, this system saves 5 minutes per 30-minute trip. See details in the following publications. |
Publications
[1] Jing Yuan, Yu Zheng, et al. T-Drive: Driving Directions Based on Taxi Trajectories. In ACM SIGSPATIAL GIS 2010, The Best Paper Runner-Up Award.
[2] Jing Yuan, Yu Zheng, et al, T-Drive: Enhancing Driving Directions with Taxi Drivers’ Intelligence. Transactions on Knowledge and Data Engineering (TKDE).
Media Reports
[1] Adding cabbie know-how to online maps, MIT Technology Review, 2010.11.6
[2] Follow that cab! Racing Google Maps on city streets, NewScientist, 2010.11.5
Further Research: Later, we expanded this research by considering the drive behavior and traffic prediction as well as other factors affecting driving, such as weather conditions. Specifically, we proposed a model incorporating day of the week, time of day, weather conditions, and individual driving strategies (both of the taxi drivers and of the end user for whom the route is being computed). Using this model, our system predicts the traffic conditions of a future time (when the computed route is actually driven) and performs a self-adaptive driving direction service for a particular user. This service gradually learns a user’s driving behavior from the user’s GPS logs and customizes the fastest route for the user. Refer to the following publication for details.
Publications
[1] Jing Yuan, Yu Zheng, et al. Driving with Knowledge from the Physical World. 17th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2011).
Media Reports
[1] “A driving route made just for you“, MIT Technology Review, 2011.8.30.
A Passenger-Cabbie Recommender System
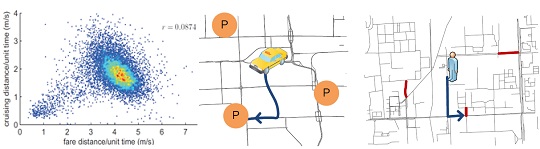
Abstract: We present a recommender for taxi drivers and people expecting to take a taxi, using the knowledge of 1) passengers’ mobility patterns and 2) taxi drivers’ pick-up behaviors learned from the GPS trajectories of taxicabs. First, this recommender provides taxi drivers with some locations (and the routes to these locations), towards which they are more likely to pick up passengers quickly (during the routes or at the parking places) and maximize the profit. Second, it recommends people with some locations (within a walking distance) where they can easily find vacant taxis. In our method, we propose a parking place detection algorithm and learn the above knowledge (represented by probabilities) from trajectories. Then, we feed the knowledge into a probabilistic model which estimates the profit of a parking place for a particular driver based on where and when the driver requests for the recommendation. We validate our recommender using trajectories generated by 12,000 taxis in 110 days.
Publications
[1] Jing Yuan, Yu Zheng, Liuhang Zhang, Xing Xie. Where to Find My Next Passenger? , 13th ACM International Conference on Ubiquitous Computing (UbiComp 2011).
[2] Nicholas Jing Yuan, Yu Zheng, Liuhang Zhang, Xing Xie. T-Finder: A Recommender System for Finding Passengers and Vacant Taxis. accepted by IEEE Transactions on Knowledge and Data Engineering (TKDE).
Traffic Prediction in a Bike Sharing System
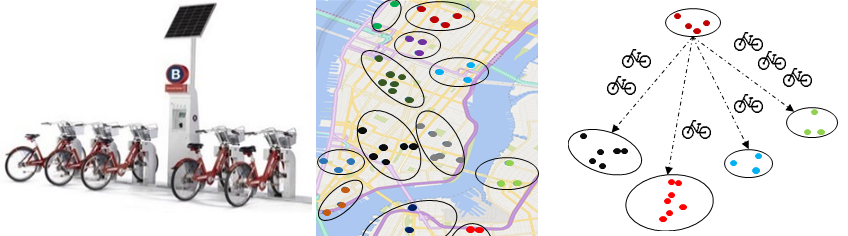
Abstract: Bike-sharing systems are widely deployed in many major cities, providing a convenient transportation mode for citizens’ commutes. As the rents/returns of bikes at different stations in different periods are unbalanced, the bikes in a system need to be rebalanced frequently. In this paper, we propose a hierarchical prediction model to predict the number of bikes that will be rent from/returned to each station cluster in a future period so that reallocation can be executed in advance.
Methodology: We first propose a bipartite clustering algorithm to cluster bike stations into groups, formulating a two-level hierarchy of stations. The total number of bikes that will be rent in a city is predicted by a Gradient Boosting Regression Tree (GBRT). Then a multi-similarity-based inference model is proposed to predict the rent proportion across clusters and the inter-cluster transition, based on which the number of bikes rent from/ returned to each cluster can be easily inferred.
Publication:
[1] Yexin Lee, Yu Zheng, Huichu Zhang, Lei Chen. Traffic Prediction in a Bike Sharing System, In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015) (Data)(Codes)
Data Driven Urban Planning
Data-Driven Urban Planning
Discovering Region of Different Functions in a City Using Human Mobility and POIs

Goal: We propose a framework (titled DRoF) that Discovers Regions of different Functions, such as educational areas and business districts, in a city using both human mobility among regions and points of interests (POIs) located in a region. The results generated by our framework can benefit a variety of applications, including urban planning, location choosing for a business, and social recommendations.
Insight: We segment a city into disjointed regions according to major roads, such as highways and urban express ways. We infer the functions of each region using a topic-based inference model, which regards a region as a document, a function as a topic, categories of POIs (e.g., restaurants and shopping malls) as metadata (like authors, affiliations, and key words), and human mobility patterns (when people reach/leave a region and where people come from and leave for) as words. As a result, a region is represented by a distribution of functions, and a function is featured by a distribution of mobility patterns.
Publications:
[1] Jing Yuan, Yu Zheng, Xing Xie. Discovering regions of different functions in a city using human mobility and POIs. 18th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2012).
[2] Nicholas Jing Yuan, Yu Zheng, Xing Xie, Yingzi Wang, Kai Zheng, Hui Xiong. Discovering Urban Functional Zones Using Latent Activity Trajectories, IEEE Transactions on Knowledge and Data Engineering (TKDE), 2016.
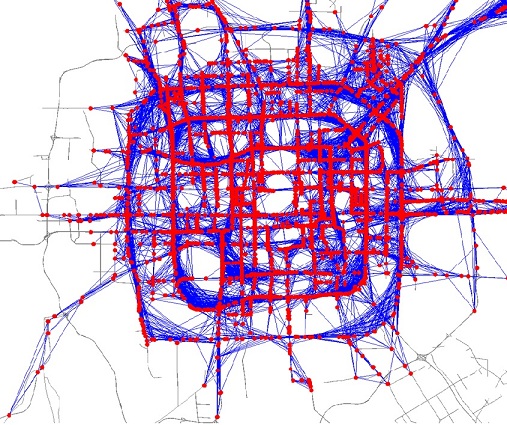
Glean the underlying problems in a City’s Road Network
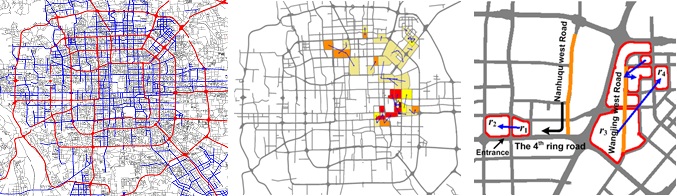
Abstract: Urban computing for city planning is one of the most significant applications in Ubiquitous computing. In this paper we detect flawed urban planning using the GPS trajectories of taxicabs traveling in urban areas. The detected results consist of 1) pairs of regions with salient traffic problems and 2) the linking structure as well as correlation among them. These results can evaluate the effectiveness of the carried out planning, such as a newly built road and subway lines in a city, and remind city planners of a problem that has not been recognized when they conceive future plans. We conduct our method using the trajectories generated by 30,000 taxis from March to May in 2009 and 2010 in Beijing, and evaluate our results with the real urban planning of Beijing.
Publications
[1] Yu Zheng, Yanchi Liu, Jing Yuan, Xing Xie, Urban Computing with Taxicabs, 13th ACM International Conference on Ubiquitous Computing (UbiComp 2011), Beijing, China, Sep. 2011. The best paper nominee award.
[2] A technical report describing the map segmentation and trajectory projection details.
Media Reports
[1] “Taxicab data helps ease traffic“. Future of Technology on NBCNEWS.com. 2011.9.30
[2] “GPS Data on Beijing Cabs Reveals the Cause of the Traffic Jams“. MIT Technology Review, 2011.9.27. Featured on the first page.
[3] “Urban computing based on taxicabs”. Reported by ACM TechNews. 2011.9.27
Detect Urban Black holes Based on Human Mobility
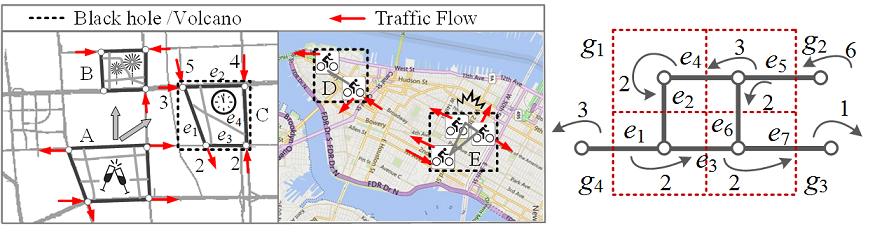
Abstract: An urban black hole is a subgraph (or a region) that has the overall inflow greater than the overall outflow by a threshold, while a volcano is a subgraph with the overall outflow greater than the overall inflow by a threshold. The online detection of black holes/volcanos can timely reflect anomalous events, such as disasters, catastrophic accidents, and therefore help keep public safety. The patterns of black holes/volcanos and the relations between them reveal human mobility patterns in a city, thus help formulate a better city planning or improve a system’s operation efficiency.
Publication:
[1] Liang Hong, Yu Zheng, Duncan Yung, Jingbo Shang, Lei Zou. Detecting Urban Black Holes Based on Human Mobility Data. In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015). (Codes) (Data)
Planning Bike Lanes based on Sharing-Bikes’ Trajectories
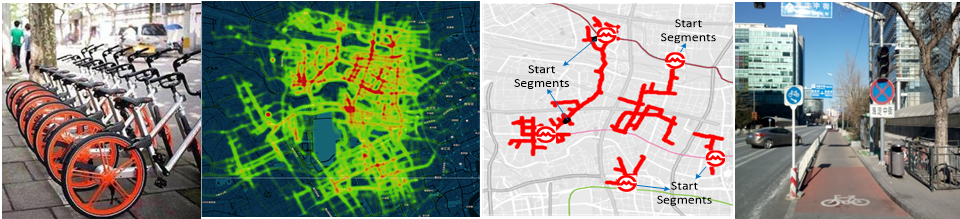
Cycling as a green transportation mode has been promoted by many governments all over the world. As a result, constructing effective bike lanes has become a crucial task for governments promoting the cycling life style, as well-planned bike paths can reduce traffic congestion and decrease safety risks for both cyclists and motor vehicle drivers. Unfortunately, existing trajectory mining approaches for bike lane planning do not consider key realistic government constraints: 1) budget limitations, 2) construction convenience, and 3) bike lane utilization. In this project, we propose a data-driven approach to develop bike lane construction plans based on large-scale real world bike trajectory data. We enforce these constraints to formulate our problem and introduce a flexible objective function to tune the benefit between coverage of the number of users and the length of their trajectories. We prove the NP-hardness of the problem and propose greedy-based heuristics to address it. Finally, we deploy our system on Microsoft Azure, providing extensive experiments and case studies to demonstrate the effectiveness of our approach.
Publications:
[1] Jie Bao, Tianfu He, Sijie Ruan, Yanhua Li, Yu Zheng. Planning bike lanes based on Sharing-bike’s trajectories. in Proceedings of the 23th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2017).
Urban Energy Based on Big Data
Urban Energy Based on Big Data
A. Gas Consumption and Vehicle Emissions on Roads
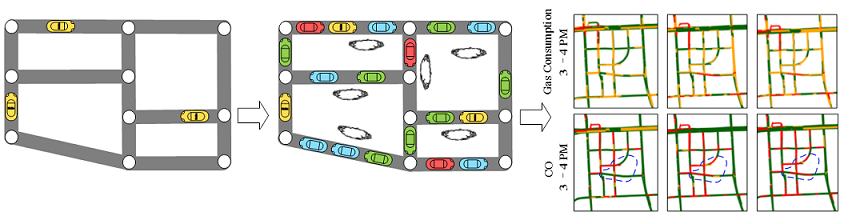
Goal: We instantly infers the gas consumption and pollution emission of vehicles traveling on a city’s road network in a current time slot, using GPS trajectories from a sample of vehicles (e.g., taxicabs). The knowledge can be used to suggest cost-efficient driving routes as well as identifying road segments where gas has been wasted significantly.
Methodology: We propose a Travel Speed Estimation (TSE) model based on a context-aware matrix factorization approach. TSE leverages features learned from other data sources, e.g., map data and historical trajectories, to deal with the data sparsity problem. We then propose a Traffic Volume Inference (TVI) model to infer the number of vehicles passing each road segment per minute. TVI is an unsupervised Bayesian Network that incorporates multiple factors, such as travel speed, weather conditions and geographical features of a road. Given the travel speed and traffic volume of a road segment, gas consumption and emissions are calculated based on existing environmental theories. Refer to publication [1] for details.
B. Sensing Urban Refueling Behavior
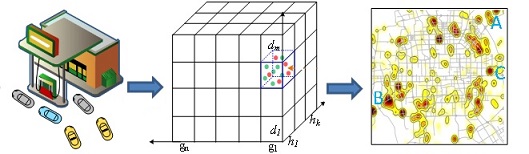
We propose a step toward real-time sensing of refueling behavior and citywide petrol consumption. We use reported trajectories from a fleet of GPS-equipped taxicabs to detect gas station visits, measure the time spent, and estimate overall demand. For times and stations with sparse data, we use collaborative filtering to estimate conditions. Our system provides real-time estimates of gas stations’ wait times, from which recommendations could be made, an indicator of overall gas usage, from which macro-scale economic decisions could be made, and a geographic view of the efficiency of gas station placement. refer to publication [2] and [3] for details.
Publications:
[1] Jingbo Shang*, Yu Zheng, Wenzhu Tong, Eric Chang. Inferring Gas Consumption and Pollution Emission of Vehicles throughout a City. In the Proceeding of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014).
[2] Fuzhen Zhang, David Wilkie, Yu Zheng, Xing Xie. Sensing the Pulse of Urban Refueling Behavior. 15th ACM International Conference on Ubiquitous Computing (UbiComp 2013)
[3] Fuzheng Zhang*, Nicholas Jing Yuan, David Wilkie, Yu Zheng, Xing Xie. Sensing the Pulse of Urban Refueling Behavior: A Perspective from Taxi Mobility. ACM Transaction on Intelligent Systems and Technology (ACM TIST). 2015.
Media coverage: featured by United Nations.
Urban Anomalies and Public Security
Urban Anomalies and Security
A. Forecasting Flow of Crowds Based on Big Data
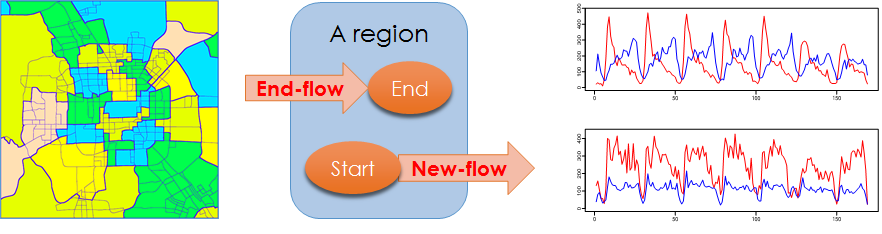
Abstract: Predicting the movement of crowds in a city is strategically important for traffic management, risk assessment, and public safety. In this project, we propose predicting two types of flows of crowds in every region of a city based on big data, including human mobility data, weather conditions, and road network data. To develop a practical solution for citywide traffic prediction, we first partition the map of a city into regions using both its road network and historical records of human mobility. Our problem is different than the predictions of each individual’s movements and each road segment’s traffic conditions, which are computationally costly and not necessary from the perspective of public safety on a citywide scale. To model the multiple complex factors affecting crowd flows, we decompose flows into three components: seasonal (periodic patterns), trend (changes in periodic patterns), and residual flows (instantaneous changes). The seasonal and trend models are built as intrinsic Gaussian Markov random fields which can cope with noisy and missing data, whereas a residual model exploits the spatio-temporal dependence among different flows and regions, as well as the effect of weather.
Publications
[1] Minh X. Hoang, Yu Zheng, Ambuj K. Singh. FCCF: Forecasting Citywide Crowd Flows Based on Big Data. in Proceedings of the 24th ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2016) (PPT)
Download Code and Data!
B. Deep Learning-Based Crowd Flow Prediction
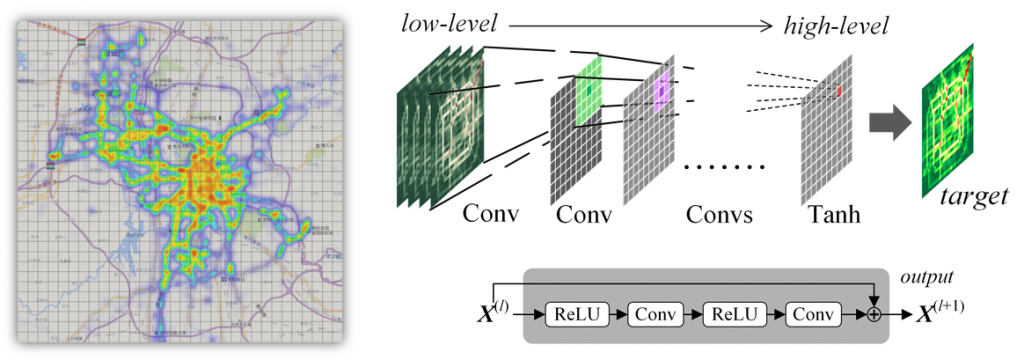
Abstract: Forecasting the flow of crowds is of great importance to traffic management and public safety, yet a very challenging task affected by many complex factors, such as inter-region traffic, events and weather. In this paper, we propose a deep-learning-based approach, called ST-ResNet, to collectively forecast the in-flow and out-flow of crowds in each and every region through a city. We design the end-to-end structure of ST-ResNet based on unique properties of spatio-temporal data. More specifically, we employ the framework of the residual neural networks to model the temporal smoothness, period, and trend properties of crowd traffic, respectively. For each property, we design a branch of residual convolutional blocks, each of which models the spatial properties of crowd traffic. ST-ResNet learns to dynamically aggregate the output of the three residual neural networks based on data, assigning different weights to different branches and regions. The aggregation is further combined with external factors, such as weather and day of week, to predict the final traffic of crowds in each and every region. We evaluate ST-ResNet based on two types of crowd flows in Beijing and NYC, finding its performance outperforming the state-of-the-art.
Publications:
[1] Junbo Zhang, Yu Zheng, Dekang Qi. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI 2017) [code][data][system]
[2] Junbo Zhang, Yu Zheng, Dekang Qi, Ruiyuan Li, Xiuwen Yi. DNN-Based Prediction Model for Spatial-Temporal Data. in Proceedings of the 24th ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2016) Demo Paper (arXiv version)
C. Detect Collective Anomalies from Cross-Domain Data
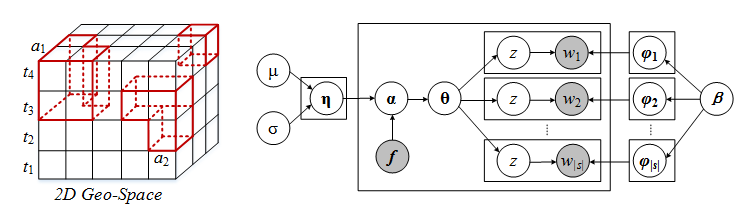
Abstract: The collective anomaly denotes a collection of nearby locations that are anomalous during a few consecutive time intervals in terms of phenomena collectively witnessed by multiple datasets. The collective anomalies suggest there are underlying problems that may not be identified based on a single data source or in a single location. It also associates individual locations and time intervals, formulating a panoramic view of an event. To detect a collective anomaly is very challenging, however, as different datasets have different densities, distributions, and scales. Additionally, to find the spatio-temporal scope of a collective anomaly is time consuming as there are many ways to combine regions and time slots.
Publications
[1] Yu Zheng, Huichu Zhang, Yong Yu. Detecting Collective Anomalies from Multiple Spatio-Temporal Datasets across Different Domains. In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015). (Data) (Codes)
d. Crowd Sensing of Traffic Anomalies in a City
[1] Detecting Traffic Anomalies: We detect anomalies in a city according to the taxi trajectories. The anomaly could be caused by unexpected or sudden accidents, such as traffic control, protests, concerts, parades, celebrations, and large-scale sale promotion. In many cases, the anomaly occurs before the corresponding accident actually happens. If detecting the unusual mobility pattern of people in this region in advance, we can solve the problem early and avoid the happening of the tragedy.
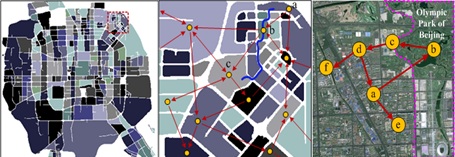
[a] Wei Liu, Yu Zheng, Sanjay Chawla, Jing Yuan and Xing Xie. Discovering Spatio-Temporal Causal Interactions in Traffic Data Streams. In KDD 2011.
[b] Linsey Xiaolin Pang, Sanjay Chawla, Wei Liu, and Yu Zheng. On Mining Anomalous Patterns in Road Traffic Streams. In the 7th International Conference on Advanced Data Mining and Applications (ADMA 2011). The best paper award
[2] Diagnose and Describe Traffic Anomalies: In publication , we identify the source traffic flow that results in an anomaly. In publication [d], we address the problem of detecting and describing traffic anomalies using crowd sensing with two forms of data, human mobility and social media.

Sanjay Chawla, Yu Zheng, and Jiafeng Hu. Inferring the root cause in road traffic anomalies, IEEE International Conference on Data Mining (ICDM 2012).
[d] Bei Pan, Yu Zheng, David Wilkie, and Cyrus Shahabi. Crowd Sensing of Traffic Anomalies based on Human Mobility and Social Media. ACM SIGSPATIAL GIS 2013
Urban Economy
Ranking Real Estates Using Big Data
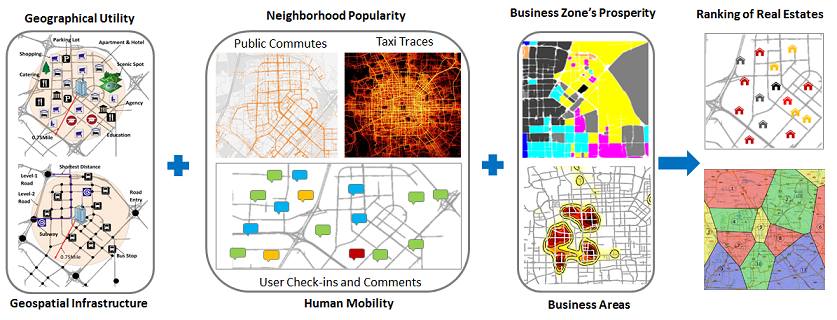
Abstract: Ranking residential real estate based on a diversity of big data around a real estate: 1) geographical data, such as road network and points of interests (POI), 2) human mobility data, like public commuting data and taxi traces, and 3) people’s comments and reviews on these real estates and their surrounding POIs in online services. These datasets reveal the popularity and quality of the location where a real estate is located.
Publications:
[1] Yanjie Fu, Hui Xiong, Yong Ge, Zijun Yao, Yu Zheng. Exploiting Geographic Dependencies for Real Estate Appraisal: A Mutual Perspective of Ranking and Clustering. In the Proceeding of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014).
[2] Yanjie Fu, Yong Ge, Yu Zheng, Zijun Yao, Yanchi Liu, Hui Xiong, Nicholas Jing Yuan. Sparse Real Estate Ranking with Online User Reviews and Offline Moving Behaviors. IEEE International Conference on Data Mining (ICDM 2014).
Large-Scale and Dynamic City Express
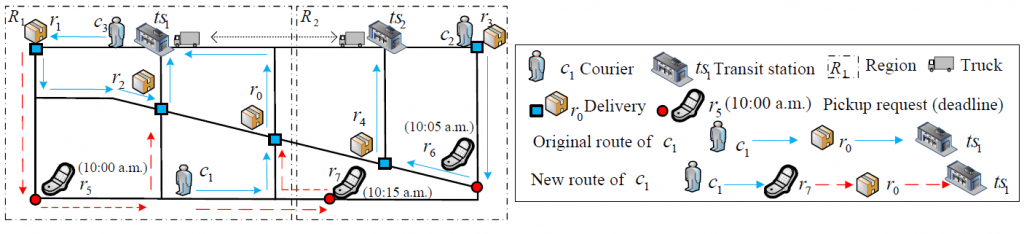
Abstract: Due to the large number of requirements for city express services in recent years, the current city express system is found to be unsatisfactory for both the service providers and customers. In this paper, we are the first to systematically study the large-scale dynamic city express problem. We aim to increase both the effectiveness and the efficiency of the scheduling algorithm. The challenges of the problem stem from the highly dynamic environment, the NP-completeness with respect to the number of requests, and real-time demands for the scheduling result. our solution can save 37.5% manpower to achieve 80% satisfaction ratio compared to the basic solution.
Publications:
[1] Siyuan Zhang, Lu Qin, Yu Zheng, and Hong Cheng. Effective and Efficient: Large-scale Dynamic City Express. IEEE Transactions on Data Engineering (TKDE)
Selecting Locations for Billboards Based on Trajectories of Vehicles
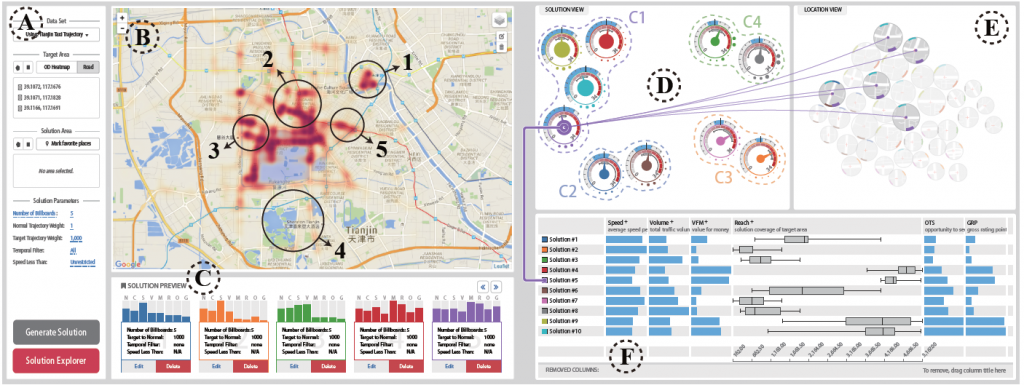
Abstract: The problem of formulating solutions immediately and comparing them rapidly for billboard placements has plagued advertising planners for a long time, owing to the lack of efficient tools for in-depth analyses to make informed decisions. In this study, we attempt to employ visual analytics that combines the state-of-the-art mining and visualization techniques to tackle this problem using large-scale GPS trajectory data. In particular, we present SmartAdP, an interactive visual analytics system that deals with the two major challenges including finding good solutions in a huge solution space and comparing the solutions in a visual and intuitive manner. An interactive framework that integrates a novel visualization-driven data mining model enables advertising planners to effectively and efficiently formulate good candidate solutions.
Publications:
[1] Dongyu Liu, Di Weng, Yuhong Li, Yingcai Wu, Jie Bao, Yu Zheng, Huaming Qu, “SmartAdP: Visual Analytics of Large-scale Taxi Trajectories for Selecting Billboard Locations”, in The IEEE Conference on Visual Analytics Science and Technology (IEEE VAST 2016).
Constructing Popular Routes from User Check-in Data
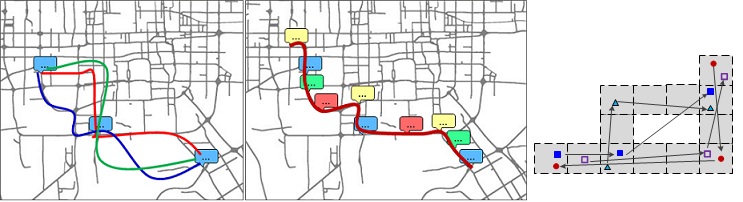
Abstract: We present a Route Inference framework based on Collective Knowledge (RICK) to construct the popular routes from uncertain trajectories, e.g., a user’s check-in sequence in FourSquare, geo-tagged photos in Flickr, or the migratory trails of a bird. Explicitly, given a location sequence and a time span, the RICK is able to construct the top-k routes which sequentially pass through the locations within the specified time span, by aggregating such uncertain trajectories in a mutual reinforcement way (i.e., uncertain + uncertain → certain). Our work can benefit trip planning, traffic management, and animal movement studies.
Publications:
[1] Ling-Yin Wei, Yu Zheng, Wen-Chih Peng, Constructing Popular Routes from Uncertain Trajectories. 18th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2012). (Data)
[2] Hechen Liu, Ling-Yin We, Yu Zheng, Markus Schneider, Wen-Chih Peng. Route Discovery from Mining Uncertain Trajectories. Demo Paper, in IEEE International Conference on Data Mining (ICDM 2011).
Released Datasets
[1] T-Drive Taxi Trajectroies: This is a sample of T-Drive taxi trajectory dataset which was generated by over 10,000 taxis in a period of one week in Beijing.
[2] GeoLife Trajectory Dataset: This is a GPS trajectory dataset collected in (Microsoft Research Asia) GeoLife project by 167 users in a period of over two years (from April 2007 to Dec. 2010). This trajectory dataset can be used for many research theme, such as mobility pattern mining, user activity recognition, location-based social networks, location privacy, and location recommendation.
[3] Taxi request simulator: This simulator can generate people’s request for taxicabs on different road segments, using the knowledge mined from a large-scale real taxi trajectories. Each query consists of an origin, destination, and a timestamp.
[4] Check-in data from Foursquare: Each check-in includes a venue ID, the category of the venue, a timestamp, and a user ID.
[5] Air quality data of Beijing and Shanghai: The data set is comprised of one-year (2013-2-8 to 2014-2-8) air quality data from air quality monitoring stations in Beijing and Shanghai.
[6] Traffic and geographical features of each road segments: The package is comprised of six parts of data that were extracted from the GPS trajectories of taxicabs, road networks, POIs of Beijing, and video clips recording real traffic on roads.
[7] Noise complaint data and geographical data of NYC: This package is comprised of three parts of data. 1) tensors representing the 311 complaints on urban noise; 2) geographical feature of each region in NYC; 3) Real noise levels of 36 locations in NYC. Please cite the following two papers when using the dataset.
[8] Air quality data, meteorological data and weather forecasts of 43 cities in China. The dataset was used for air quality forecast and real-time inference. It also can be used for test cross-domain data fusion methods.
[9] Bike Sharing data coupled with weather conditions. The dataset contains bike usage (denoted by the number of check-outs and check-ins) at each bike sharing station in NYC and Chicago. The weather condition data during the period, in which the bike sharing data is collected, is also shared.
[10] Three datasets for detecting collective anomalies: This dataset is comprised of five parts of data, named Taxi Trip Data, Bike sharing data, 311 data, POIs and road network data of NYC.
[11] Inflow and outflow of crowds in each and every region of a city: This data set consists of two types of crowd flows. One is a five-year taxis flow in Beijing. The other is bike usage in a bike sharing system in New York City. A research on predicting flow of crowds have been conducted based on this dataset. Please cite the following paper when using the dataset. (code)(data)(system)
Related People
- Yu Zheng, Group Manager, Senior Researcher
- Jie Bao, Associate Researcher
- Junbo Zhang, Associate Researcher
- Jing Yuan, Researcher
- Ruiyuan Li, Software Developer Engineer
- Qiwei Jin, Software Developer Engineer
There are many research interns who have worked with us in this project. We truly appreciate their contribution though we cannot list each of them on this page.
Yubiao Chen, Xuxu Chen, Hsun-Ping Hsieh, Furui Liu, Tong Liu, Yiulun Wang, Wenzhu Tong, Jingbo Shang, Xiuwen Yi, Zhenni Feng, Yexiang Xue, Yanjie Fu, Fuzheng Zhang.
Slide Decks and Videos of Speeches
2019
- Keynote at AAAI2019: Urban Computing: Building Intelligent cities with Big Data and AI 2019.1, [PPT].
2017
- Keynote at UrbComp2017: Urban Computing: Enabling Intelligent Cities with AI and Big Data (50 minutes), 2017.8, video.
- Tutorial at KDD 2017: Urban Computing: Enabling Intelligent Cities with AI and Big Data (4hours), 2017.8
- Tutorial at DASFFA 2017: Urban Computing: Enabling Intelligent Cities with AI and Big Data (2hours), 2017.6
2016
- 2016.11.1: keynote speech at IWGS 2016 in conjunction with ACM SIGSPATIAL 2016
- 2016.9.18:Urban Computing for Urban Planning (60min)
- 2016.8.30: Urban Big Data Platform (30min)
- 2016.8.15: Urban Computing: An Overview (Invited Talk at KDD 2016)
- 2016.8.1:Urban Computing for Transportation
- 2016.2.1:a slide deck for a 90-minute overview on Urban Computing.
- 2016.1.1: Tutorial on Trajectory Data Mining (Download free slide decks)
2015
- 2015.10:Slides for 2-hour Overview on Urban Computing
- 2015.10: MOOC about Urban Computing (at XuetangX)(at iCourse)
- 20-minute presentation about Urban Air
- 2015.1: Dr. Zheng’s Speech at the Roundtable of Thought Leaders on Innovation in Cities: (Video)
- 60-minute presentation for Universities
- 70-minute presentation: urban computing for the environment
- 60-minute presentation: urban computing for tackling air pollution
2014
- 2014.12: Prof. Zheng’s Distinguished Lecture at Hong Kong Baptist University (Video)
- 1-hour MOOC on Urban Computing.
- A slide deck for a 1-hour presentation
- A ppt for a 30-minute presentation
2013
2012
- A slide deck for a 20-minute presentation
- A slide deck for a 3-hour tutorial
People

Yu Zheng
Vice President of JD.COM and Chief Data Scientist at JD Technology
